RNA Velocity Basics
Here you will learn the basics of RNA velocity analysis.
For illustration, it is applied to endocrine development in the pancreas, with lineage commitment to four major fates: α, β, δ and ε-cells. See here for more details. It can be applied to your own data along the same lines.
The notebook is also available at Google Colab and nbviewer.
[ ]:
# update to the latest version, if not done yet.
!pip install scvelo --upgrade --quiet
[1]:
import scvelo as scv
scv.logging.print_version()
Running scvelo 0.2.0 (python 3.8.2) on 2020-05-16 12:55.
[2]:
scv.settings.verbosity = 3 # show errors(0), warnings(1), info(2), hints(3)
scv.settings.presenter_view = True # set max width size for presenter view
scv.set_figure_params('scvelo') # for beautified visualization
Load the Data
The analysis is based on the in-built pancreas data. To run velocity analysis on your own data, read your file (loom, h5ad, csv …) to an AnnData object with adata = scv.read('path/file.loom', cache=True). If you want to merge your loom file into an already existing AnnData object, use scv.utils.merge(adata, adata_loom).
[3]:
adata = scv.datasets.pancreas()
adata
[3]:
AnnData object with n_obs × n_vars = 3696 × 27998
obs: 'clusters_coarse', 'clusters', 'S_score', 'G2M_score'
var: 'highly_variable_genes'
uns: 'clusters_coarse_colors', 'clusters_colors', 'day_colors', 'neighbors', 'pca'
obsm: 'X_pca', 'X_umap'
layers: 'spliced', 'unspliced'
scVelo is based on adata, an object that stores a data matrix adata.X, annotation of observations adata.obs, variables adata.var, and unstructured annotations adata.uns. Names of observations and variables can be accessed via adata.obs_names and adata.var_names, respectively. AnnData objects can be sliced like dataframes, for example, adata_subset = adata[:, list_of_gene_names]. For more details, see the anndata docs.
[4]:
scv.pl.proportions(adata)

Here, the proportions of spliced/unspliced counts are displayed. Depending on the protocol used (Drop-Seq, Smart-Seq), we typically have between 10%-25% of unspliced molecules containing intronic sequences. We also advice you to examine the variations on cluster level to verify consistency in splicing efficiency. Here, we find variations as expected, with slightly lower unspliced proportions at cycling ductal cells, then higher proportion at cell fate commitment in Ngn3-high and Pre-endocrine cells where many genes start to be transcribed.
Preprocess the Data
Preprocessing requisites consist of gene selection by detection (with a minimum number of counts) and high variability (dispersion), normalizing every cell by its total size and logarithmizing X. Filtering and normalization is applied in the same vein to spliced/unspliced counts and X. Logarithmizing is only applied to X. If X is already preprocessed from former analysis, it will not be touched.
All of this is summarized in a single function scv.pp.filter_and_normalize, which essentially runs the following:
scv.pp.filter_genes(adata, min_shared_counts=20)
scv.pp.normalize_per_cell(adata)
scv.pp.filter_genes_dispersion(adata, n_top_genes=2000)
scv.pp.log1p(adata)
Further, we need the first and second order moments (means and uncentered variances) computed among nearest neighbors in PCA space, summarized in scv.pp.moments, which internally computes scv.pp.pca and scv.pp.neighbors. First order is needed for deterministic velocity estimation, while stochastic estimation also requires second order moments.
[5]:
scv.pp.filter_and_normalize(adata, min_shared_counts=20, n_top_genes=2000)
scv.pp.moments(adata, n_pcs=30, n_neighbors=30)
Filtered out 20801 genes that are detected in less than 20 counts (shared).
Normalized count data: X, spliced, unspliced.
Logarithmized X.
computing neighbors
finished (0:00:03) --> added
'distances' and 'connectivities', weighted adjacency matrices (adata.obsp)
computing moments based on connectivities
finished (0:00:00) --> added
'Ms' and 'Mu', moments of spliced/unspliced abundances (adata.layers)
Further preprocessing (such as batch effect correction) may be used to remove unwanted sources of variability. See the best practices for further details. Note, that any additional preprocessing step only affects X and is not applied to spliced/unspliced counts.
Estimate RNA velocity
Velocities are vectors in gene expression space and represent the direction and speed of movement of the individual cells. The velocities are obtained by modeling transcriptional dynamics of splicing kinetics, either stochastically (default) or deterministically (by setting mode='deterministic'). For each gene, a steady-state-ratio of pre-mature (unspliced) and mature (spliced) mRNA counts is fitted, which constitutes a constant transcriptional state. Velocities are then obtained as
residuals from this ratio. Positive velocity indicates that a gene is up-regulated, which occurs for cells that show higher abundance of unspliced mRNA for that gene than expected in steady state. Conversely, negative velocity indicates that a gene is down-regulated.
The solution to the full dynamical model is obtained by setting mode='dynamical', which requires to run scv.tl.recover_dynamics(adata) beforehand. We will elaborate more on the dynamical model in the next tutorial.
[6]:
scv.tl.velocity(adata)
computing velocities
finished (0:00:01) --> added
'velocity', velocity vectors for each individual cell (adata.layers)
The computed velocities are stored in adata.layers just like the count matrices.
The combination of velocities across genes can then be used to estimate the future state of an individual cell. In order to project the velocities into a lower-dimensional embedding, transition probabilities of cell-to-cell transitions are estimated. That is, for each velocity vector we find the likely cell transitions that are accordance with that direction. The transition probabilities are computed using cosine correlation between the potential cell-to-cell transitions and the velocity vector,
and are stored in a matrix denoted as velocity graph. The resulting velocity graph has dimension \(n_{obs} \times n_{obs}\) and summarizes the possible cell state changes that are well explained through the velocity vectors (for runtime speedup it can also be computed on reduced PCA space by setting approx=True).
[7]:
scv.tl.velocity_graph(adata)
computing velocity graph
finished (0:00:10) --> added
'velocity_graph', sparse matrix with cosine correlations (adata.uns)
For a variety of applications, the velocity graph can be converted to a transition matrix by applying a Gaussian kernel to transform the cosine correlations into actual transition probabilities. You can access the Markov transition matrix via scv.utils.get_transition_matrix.
As mentioned, it is internally used to project the velocities into a low-dimensional embedding by applying the mean transition with respect to the transition probabilities, obtained with scv.tl.velocity_embedding. Further, we can trace cells along the Markov chain to their origins and potential fates, thereby getting root cells and end points within a trajectory, obtained via scv.tl.terminal_states.
Project the velocities
Finally, the velocities are projected onto any embedding, specified by basis, and visualized in one of these ways: - on cellular level with scv.pl.velocity_embedding, - as gridlines with scv.pl.velocity_embedding_grid, - or as streamlines with scv.pl.velocity_embedding_stream.
Note, that the data has an already pre-computed UMAP embedding, and annotated clusters. When applying to your own data, these can be obtained with scv.tl.umap and scv.tl.louvain. For more details, see the scanpy tutorial. Further, all plotting functions are defaulted to using basis='umap' and color='clusters', which you can set accordingly.
[8]:
scv.pl.velocity_embedding_stream(adata, basis='umap')
computing velocity embedding
finished (0:00:00) --> added
'velocity_umap', embedded velocity vectors (adata.obsm)
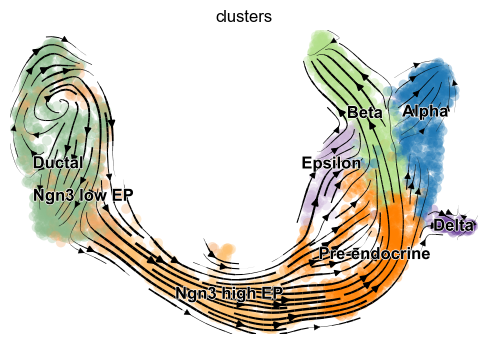
The velocity vector field displayed as streamlines yields fine-grained insights into the developmental processes. It accurately delineates the cycling population of ductal cells and endocrine progenitors. Further, it illuminates cell states of lineage commitment, cell-cycle exit, and endocrine cell differentiation.
The most fine-grained resolution of the velocity vector field we get at single-cell level, with each arrow showing the direction and speed of movement of an individual cell. That reveals, e.g., the early endocrine commitment of Ngn3-cells (yellow) and a clear-cut difference between near-terminal α-cells (blue) and transient β-cells (green).
[9]:
scv.pl.velocity_embedding(adata, arrow_length=3, arrow_size=2, dpi=120)
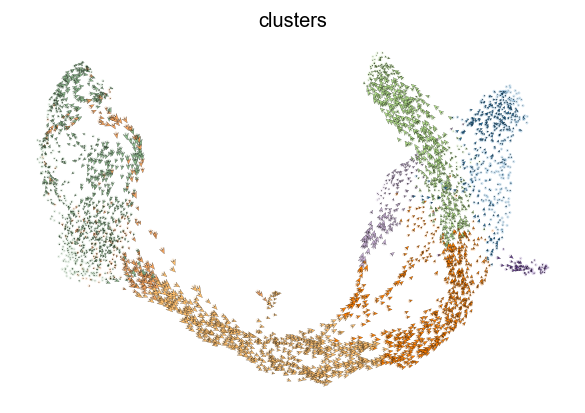
Interprete the velocities
This is perhaps the most important part as we advise the user not to limit biological conclusions to the projected velocities, but to examine individual gene dynamics via phase portraits to understand how inferred directions are supported by particular genes.
See the gif here to get an idea of how to interpret a spliced vs. unspliced phase portrait. Gene activity is orchestrated by transcriptional regulation. Transcriptional induction for a particular gene results in an increase of (newly transcribed) precursor unspliced mRNAs while, conversely, repression or absence of transcription results in a decrease of unspliced mRNAs. Spliced mRNAs is produced from unspliced mRNA and follows the same trend with a time lag. Time is a hidden/latent variable. Thus, the dynamics needs to be inferred from what is actually measured: spliced and unspliced mRNAs as displayed in the phase portrait.
{kind=link}
Now, let us examine the phase portraits of some marker genes, visualized with scv.pl.velocity(adata, gene_names) or scv.pl.scatter(adata, gene_names).
[10]:
scv.pl.velocity(adata, ['Cpe', 'Gnao1', 'Ins2', 'Adk'], ncols=2)
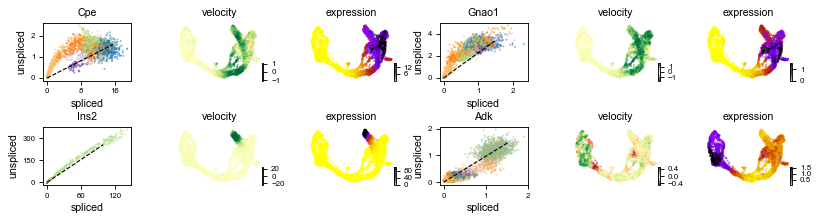
The black line corresponds to the estimated ‘steady-state’ ratio, i.e. the ratio of unspliced to spliced mRNA abundance which is in a constant transcriptional state. RNA velocity for a particular gene is determined as the residual, i.e. how much an observation deviates from that steady-state line. Positive velocity indicates that a gene is up-regulated, which occurs for cells that show higher abundance of unspliced mRNA for that gene than expected in steady state. Conversely, negative velocity indicates that a gene is down-regulated.
For instance Cpe explains the directionality in the up-regulated Ngn3 (yellow) to Pre-endocrine (orange) to β-cells (green), while Adk explains the directionality in the down-regulated Ductal (dark green) to Ngn3 (yellow) to the remaining endocrine cells.
[11]:
scv.pl.scatter(adata, 'Cpe', color=['clusters', 'velocity'],
add_outline='Ngn3 high EP, Pre-endocrine, Beta')
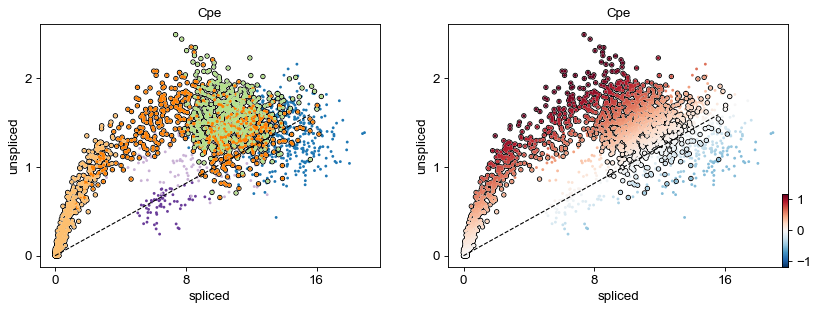
Identify important genes
We need a systematic way to identify genes that may help explain the resulting vector field and inferred lineages. To do so, we can test which genes have cluster-specific differential velocity expression, being siginificantly higher/lower compared to the remaining population. The module scv.tl.rank_velocity_genes runs a differential velocity t-test and outpus a gene ranking for each cluster. Thresholds can be set (e.g. min_corr) to restrict the test on a selection of gene candidates.
[12]:
scv.tl.rank_velocity_genes(adata, groupby='clusters', min_corr=.3)
df = scv.DataFrame(adata.uns['rank_velocity_genes']['names'])
df.head()
ranking velocity genes
finished (0:00:02) --> added
'rank_velocity_genes', sorted scores by group ids (adata.uns)
'spearmans_score', spearmans correlation scores (adata.var)
[12]:
| Ductal | Ngn3 low EP | Ngn3 high EP | Pre-endocrine | Beta | Alpha | Delta | Epsilon | |
|---|---|---|---|---|---|---|---|---|
| 0 | Notch2 | Ptpn3 | Pde1c | Pam | Pax6 | Zcchc16 | Zdbf2 | Tmcc3 |
| 1 | Sox5 | Hacd1 | Ptprs | Sdk1 | Unc5c | Nlgn1 | Spock3 | Heg1 |
| 2 | Krt19 | Hspa8 | Pclo | Baiap3 | Nnat | Nell1 | Akr1c19 | Gpr179 |
| 3 | Hspa8 | Gm8113 | Rap1gap2 | Abcc8 | Tmem108 | Prune2 | Ptprt | Ica1 |
| 4 | Ano6 | Kcnq1 | Ttyh2 | Gnas | Ptprt | Ksr2 | Snap25 | Ncoa7 |
[13]:
kwargs = dict(frameon=False, size=10, linewidth=1.5,
add_outline='Ngn3 high EP, Pre-endocrine, Beta')
scv.pl.scatter(adata, df['Ngn3 high EP'][:5], ylabel='Ngn3 high EP', **kwargs)
scv.pl.scatter(adata, df['Pre-endocrine'][:5], ylabel='Pre-endocrine', **kwargs)


The genes Ptprs, Pclo, Pam, Abcc8, Gnas, for instance, support the directionality from Ngn3 high EP (yellow) to Pre-endocrine (orange) to Beta (green).
Velocities in cycling progenitors
The cell cycle detected by RNA velocity, is biologically affirmed by cell cycle scores (standardized scores of mean expression levels of phase marker genes).
[14]:
scv.tl.score_genes_cell_cycle(adata)
scv.pl.scatter(adata, color_gradients=['S_score', 'G2M_score'], smooth=True, perc=[5, 95])
calculating cell cycle phase
--> 'S_score' and 'G2M_score', scores of cell cycle phases (adata.obs)
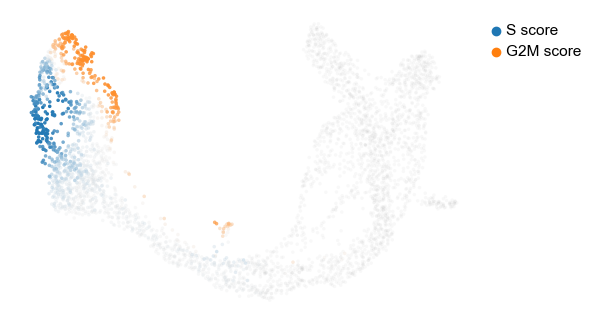
For the cycling Ductal cells, we may screen through S and G2M phase markers. The previous module also computed a spearmans correlation score, which we can use to rank/sort the phase marker genes to then display their phase portraits.
[15]:
s_genes, g2m_genes = scv.utils.get_phase_marker_genes(adata)
s_genes = scv.get_df(adata[:, s_genes], 'spearmans_score', sort_values=True).index
g2m_genes = scv.get_df(adata[:, g2m_genes], 'spearmans_score', sort_values=True).index
kwargs = dict(frameon=False, ylabel='cell cycle genes')
scv.pl.scatter(adata, list(s_genes[:2]) + list(g2m_genes[:3]), **kwargs)
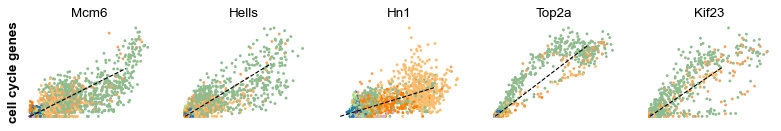
Particularly Hells and Top2a are well-suited to explain the vector field in the cycling progenitors. Top2a gets assigned a high velocity shortly before it actually peaks in the G2M phase. There, the negative velocity then perfectly matches the immediately following down-regulation.
[16]:
scv.pl.velocity(adata, ['Hells', 'Top2a'], ncols=2, add_outline=True)

Speed and coherence
Two more useful stats: - The speed or rate of differentiation is given by the length of the velocity vector. - The coherence of the vector field (i.e., how a velocity vector correlates with its neighboring velocities) provides a measure of confidence.
[17]:
scv.tl.velocity_confidence(adata)
keys = 'velocity_length', 'velocity_confidence'
scv.pl.scatter(adata, c=keys, cmap='coolwarm', perc=[5, 95])
--> added 'velocity_length' (adata.obs)
--> added 'velocity_confidence' (adata.obs)
--> added 'velocity_confidence_transition' (adata.obs)
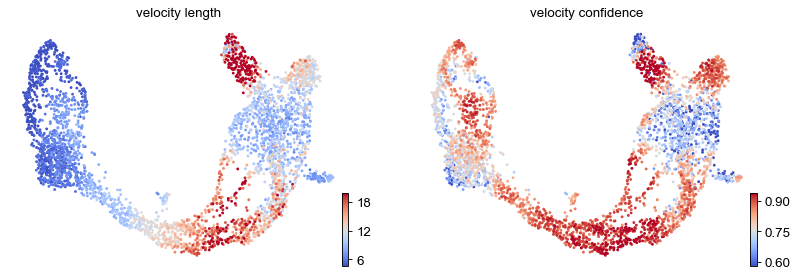
These provide insights where cells differentiate at a slower/faster pace, and where the direction is un-/determined.
On cluster-level, we find that differentiation substantially speeds up after cell cycle exit (Ngn3 low EP), keeping the pace during Beta cell production while slowing down during Alpha cell production.
[18]:
df = adata.obs.groupby('clusters')[keys].mean().T
df.style.background_gradient(cmap='coolwarm', axis=1)
[18]:
| clusters | Ductal | Ngn3 low EP | Ngn3 high EP | Pre-endocrine | Beta | Alpha | Delta | Epsilon |
|---|---|---|---|---|---|---|---|---|
| velocity_length | 5.707904 | 6.227023 | 13.257741 | 13.429206 | 14.219882 | 10.491913 | 7.623143 | 10.477606 |
| velocity_confidence | 0.775042 | 0.756474 | 0.896944 | 0.830438 | 0.725973 | 0.752715 | 0.691188 | 0.784467 |
Velocity graph and pseudotime
We can visualize the velocity graph to portray all velocity-inferred cell-to-cell connections/transitions. It can be confined to high-probability transitions by setting a threshold. The graph, for instance, indicates two phases of Epsilon cell production, coming from early and late Pre-endocrine cells.
[19]:
scv.pl.velocity_graph(adata, threshold=.1)

Further, the graph can be used to draw descendents/anscestors coming from a specified cell. Here, a pre-endocrine cell is traced to its potential fate.
[20]:
x, y = scv.utils.get_cell_transitions(adata, basis='umap', starting_cell=70)
ax = scv.pl.velocity_graph(adata, c='lightgrey', edge_width=.05, show=False)
ax = scv.pl.scatter(adata, x=x, y=y, s=120, c='ascending', cmap='gnuplot', ax=ax)
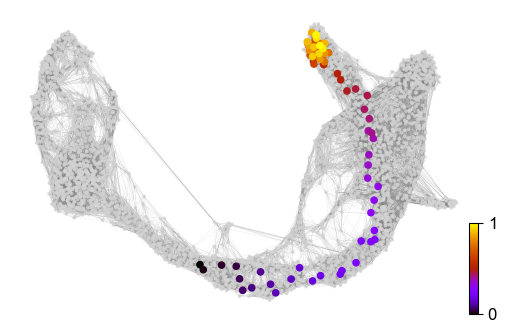
Finally, based on the velocity graph, a velocity pseudotime can be computed. After inferring a distribution over root cells from the graph, it measures the average number of steps it takes to reach a cell after walking along the graph starting from the root cells.
Contrarily to diffusion pseudotime, it implicitly infers the root cells and is based on the directed velocity graph instead of the similarity-based diffusion kernel.
[21]:
scv.tl.velocity_pseudotime(adata)
scv.pl.scatter(adata, color='velocity_pseudotime', cmap='gnuplot')
computing terminal states
identified 2 regions of root cells and 1 region of end points
finished (0:00:00) --> added
'root_cells', root cells of Markov diffusion process (adata.obs)
'end_points', end points of Markov diffusion process (adata.obs)
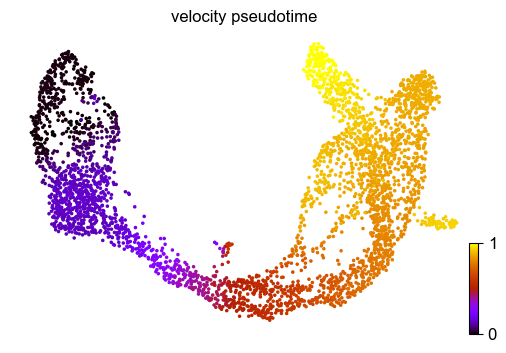
PAGA velocity graph
PAGA graph abstraction has benchmarked as top-performing method for trajectory inference. It provides a graph-like map of the data topology with weighted edges corresponding to the connectivity between two clusters. Here, PAGA is extended by velocity-inferred directionality.
[ ]:
# PAGA requires to install igraph, if not done yet.
!pip install python-igraph --upgrade --quiet
[22]:
# this is needed due to a current bug - bugfix is coming soon.
adata.uns['neighbors']['distances'] = adata.obsp['distances']
adata.uns['neighbors']['connectivities'] = adata.obsp['connectivities']
scv.tl.paga(adata, groups='clusters')
df = scv.get_df(adata, 'paga/transitions_confidence', precision=2).T
df.style.background_gradient(cmap='Blues').format('{:.2g}')
running PAGA
finished (0:00:01) --> added
'paga/transitions_confidence', connectivities adjacency (adata.uns)
'paga/connectivities', connectivities adjacency (adata.uns)
'paga/connectivities_tree', connectivities subtree (adata.uns)
[22]:
| Ductal | Ngn3 low EP | Ngn3 high EP | Pre-endocrine | Beta | Alpha | Delta | Epsilon | |
|---|---|---|---|---|---|---|---|---|
| Ductal | 0 | 0.15 | 0 | 0 | 0 | 0 | 0 | 0 |
| Ngn3 low EP | 0 | 0 | 0.24 | 0 | 0 | 0 | 0 | 0 |
| Ngn3 high EP | 0 | 0 | 0 | 0.22 | 0 | 0 | 0 | 0 |
| Pre-endocrine | 0 | 0 | 0 | 0 | 0.48 | 0.12 | 0.21 | 0.11 |
| Beta | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Alpha | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Delta | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Epsilon | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
This reads from left/row to right/column, thus e.g. assigning a confident transition from Ductal to Ngn3 low EP.
This table can be summarized by a directed graph superimposed onto the UMAP embedding.
[23]:
scv.pl.paga(adata, basis='umap', size=50, alpha=.1,
min_edge_width=2, node_size_scale=1.5)
